
Calculating Big-O of Code and Analyzing Python List Operations
References for this lecture
Problem Solving with Algorithms and Data Structures using Python
Sections 3.4-3.6: https://runestone.academy/ns/books/published/pythonds/AlgorithmAnalysis/toctree.html
Python Documentation on Time Complexity: https://wiki.python.org/moin/TimeComplexity
Review: $T(n)$ analysis
Count number of operations performed by an algorithm relative to $n$, the size of the input
E.g., $T(n) = 4n+5$ for this code
def sum_of_n_loop(n):
total = 0 # 1 operation
#this loop runs n+1 times
for i in range(n+1): #2 operations (compute the next value in the range, then assign to i)
total += i #2 operations (first add, then assign value to total)
return total
Review from last time
You ordered these $T(n)$ functions from slowest to fastest growing
$T(n) = 54$
$T(n) = 1278540$
$T(n) = 148n+12000$
$T(n) = 2081n+6$
$T(n) = 5n^2+33$
$T(n) = 23n^2+10n+8$
Takeaways
- specific time units are not important
- scaling is important - how does the run time grow?
- only the biggest term is important when $n$ gets big
Big-O: Order of magnitude
When looking at running time like $T(n) = 148n+12000$, the 12000 will be a bigger part of the overall number when $n$ is small, but when $n$ gets big, the $148n$ will dominate the 12000 part.
So, we don’t really care much about the 12000.
Similarly, whene $n$ gets big, the 148 will become a lot less significant.
Conclusion: When looking at $T(n)$, the specific constants are not very important!
Instead, look at $O($ $)$ - the Big-O
$O$ refers to the order of magnitude - it’s like $T(n)$, but you get to ignore all of the constants.
Big-O is the primary way we measure computational complexity.
- can be used for measuring time complexity or space (i.e., memory) complexity
- unless stated otherwise, assume it’s talking about time complexity - describing how the running time of an algorithm grows with larger inputs
All of these functions can be described as $O(n)$, also known as linear because they grow linearly with $n$
-
$T(n) = 148n+12000$
-
$T(n) = 4n+5$
-
$T(n) = 2081n+6$
These functions are all $O(n^2)$ - also known as quadratic
- $T(n) = 0.001n^2$
- $T(n) = 5n^2+33$
- $T(n) = 23n^2+10n+8$
Why doesn’t $T(n) = 23n^2+10n+8$ have $O(n^2+n)$
- again, when $n$ gets big, the $n^2$ term is what dominates
- You only need to include the biggest term.
These functions are all $O(1)$ - also known as constant
- $T(n) = 3$
- $T(n) = 1278540$
- $T(n) = 54$
Determining Big-O
Finding Big-O values is much easier than calculating $T(n)$ because you can ignore all the constants.
Here, we can see we have constant * $n$ + constant number of operations, which is just $O(n)$.
The only thing that depends on the size of the input is the number of times the loop iterates.
def sum_of_n_loop(n):
total = 0 # constant number of things
#this loop runs n + constant number times
for i in range(n+1): #constant number of operations
total += i #constant number of operations
return total
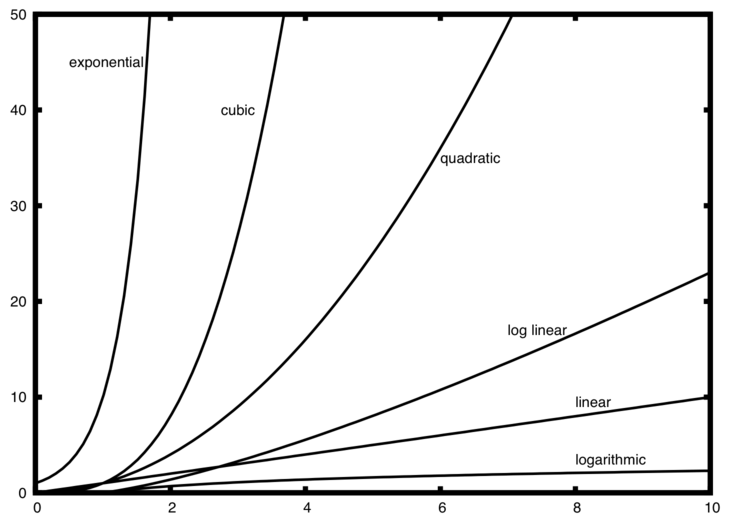
Common Big-O functions
f(n) |
Name |
|---|---|
\(1\) |
Constant |
\(\log n\) |
Logarithmic |
\(n\) |
Linear |
\(n\log n\) |
Log Linear |
\(n^{2}\) |
Quadratic |
\(n^{3}\) |
Cubic |
\(2^{n}\) |
Exponential |
Group Acitivity Problem 1
We calculated the Big-O of this search_for() function last time. Review the following with your group:
- What was $n$ for this problem?
- What input causes this algorithm to finish in the fastest amount of time?
- What input causes this algorithm to finish in the slowest amount of time?
- What’s a typical input for this function?
def search_for(item, list_to_search_in):
"""
item: the item you're supposed to search for
list_to_search_in: the list you're supposed to look through to find item
return: True or False depending on if item is contained in list_to_search_in
"""
for curr_item in list_to_search_in:
if item == curr_item:
return True
return False
#let's test it on some examples
print( search_for(42,[35,66,70,5,42,10,12]) )
print( search_for(35,[35,66,70,5,42,10,12]) )
print( search_for(12,[35,66,70,5,42,10,12]) )
print( search_for(9,[35,66,70,5,42,10,12]) )
True
True
True
False
Best, Average, and Worst Case
Different inputs (of the same size) to the same algorithm might result in different running times
Best case performance: running time on the input that allows the algorithm to finish the fastest
Worst case performance: running time on the input that requires the most time for the algorithm to finish
Average case performance: average running time over typical inputs
- often it is difficult to determine what the typical inputs are that should be considered
Unless otherwise stated, Big-O is assumed to be talking about worst case performance.
What are the best, worst, and average cases for search_for()?
Group Activity Problem 2: Anagram Detection
An anagram is a word or phrase that can be formed by rearranging the letters of a different word or phrase.
Examples of anagrams include
-
silent, listen
-
night, thing
-
the morse code, here come dots
-
eleven plus two, twelve plus one
Problem: Write a function that will tell you if two strings are anagrams.
The book provides four different solutions in Section 3.4. Three of them are reproduced below.
Each group will be assigned one of these solutions. Do the following as a group.
- Test the code on several inputs of different sizes.
- Instrument the code to measure the time it takes on different-sized inputs.
- Give examples of best, worst, and average case inputs.
- Determine what the Big-O of the algorithm is, and be ready to explain why.
If you have time, you can check out what it says in the book, but try to analyze it without looking first!
Solution 1: Checking off
This code works by converting the second string into a list and then search through the list for each character from the first string and replacing it with None when found.
For example, if given "silent" and "listen", the list would start out as
['l','i','s','t','e','n']
when searching for 's', it becomes ['l','i',None,'t','e','n']
when searching for 'i', it becomes ['l',None,None,'t','e','n']
… and so until the list becomes [None,None,None,None,None,None]
def anagramSolution1(s1,s2):
stillOK = True
if len(s1) != len(s2):
stillOK = False
alist = list(s2)
pos1 = 0
while pos1 < len(s1) and stillOK:
pos2 = 0
found = False
while pos2 < len(alist) and not found:
if s1[pos1] == alist[pos2]:
found = True
else:
pos2 = pos2 + 1
if found:
alist[pos2] = None
else:
stillOK = False
pos1 = pos1 + 1
#uncomment this if you want to see what the list looks like at each step
#print(alist)
return stillOK
print(anagramSolution1('silent','listen'))
True
Solution 2: Sort and Compare
This solution starts by converting both strings to lists and then sorting them. Once in sorted order, it goes through and checks that each corresponding item in the list is the same.
For example, if given "silent" and "listen", it would turn them into lists ['s', 'i', 'l', 'e', 'n', 't'] and ['l', 'i', 's', 't', 'e', 'n'].
Then, after sorting each list, we get ['e', 'i', 'l', 'n', 's', 't'] and ['e', 'i', 'l', 'n', 's', 't'].
We then compare e to e, then i to i, then l to l and so on. If we ever find two that don’t match, we know it isn’t an anagram. If we get to the end and they all match, it is an anagram.
def anagramSolution2(s1,s2):
alist1 = list(s1)
alist2 = list(s2)
alist1.sort()
alist2.sort()
#uncomment these if you want to see the sorted lists
#print(alist1)
#print(alist2)
pos = 0
matches = True
while pos < len(s1) and matches:
if alist1[pos]==alist2[pos]:
pos = pos + 1
else:
matches = False
return matches
print(anagramSolution2('silent','listen'))
True
Solution 4: Count and Compare
This solution creates a list of letter frequencies for each string. Since there aree 26 letters in the alphabet, the strings will each have 26 entries - the first entry is the number of occurrences of 'a', the secondd is the number of occurrences of 'b', and so on.
We can then loop through these frequency lists and compare them item by item to see if they’re the same.
For example, given inputs 'elevenplustwo' and 'twelveplusone', you end up with the frequency lists
[0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 2, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0]
and
[0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 2, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0]
looping through this list entry by entry will show that they are the same.
On the other hand, if given inputs 'granma' and 'anagram', you’d get the frequency lists
[2, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
[3, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
And you can determine they are not anagrams, because the first list has a 2 in the a position while the second one has a 3.
def anagramSolution4(s1,s2):
c1 = [0]*26
c2 = [0]*26
for i in range(len(s1)):
pos = ord(s1[i])-ord('a')
c1[pos] = c1[pos] + 1
for i in range(len(s2)):
pos = ord(s2[i])-ord('a')
c2[pos] = c2[pos] + 1
#uncomment these if you want to see the word frequency lists
#print(c1)
#print(c2)
j = 0
stillOK = True
while j<26 and stillOK:
if c1[j]==c2[j]:
j = j + 1
else:
stillOK = False
return stillOK
print(anagramSolution4('elevenplustwo','twelveplusone'))
True
Group Activity Problem 3
We’re going to run some experiments to see if we can guess what the Big-O of various Python list operations is.
- Get the timing_list_operations.py file.
- generates lots of different random lists of different sizes
- times the code and plots the running times
- as is, will generate 20 different lists each of sizes 100000, 200000, … , 1000000
list_sizes = range(100000,1000001,100000)
results = run_list_op_timing_experiments(list_sizes,20)
plot_results(list_sizes,results)
display_results(list_sizes,results)
you can change what code is timed by finding this part
### BEGIN CODE BEING TIMED
0 in test_list_copy #testing the built-in search operator
#x = test_list_copy[random_index] #testing list access
#test_list_copy.sort()
### END CODE BEING TIMED
What can you conclude about the run time of the in operator based on what you see?
Group Activity Problem 4
In the above example, you tested the 0 in test_list_copy operation. Now try the following operations. For each one, try to guess the Big-O from the run time results (you may need to try some bigger $n$ to see some of these clearly).
If you see any result like 171.45672101µ, it means $171.45672101x10^{-6}$.
x = test_list_copy[random_index] #access a random item in a list - you'll have to generate a random int first
test_list_copy.sort() #sort the list
test_list_copy.pop() #remove the last item in the list
test_list_copy.pop(0) #remove the first item in the list
Discuss: Are you surprised by any of these results?
Once you have an idea of what the Big-O is for these operations, look to see what the textbook authors say it is here: https://runestone.academy/ns/books/published/pythonds/AlgorithmAnalysis/Lists.html
Or, consult the official Python documentation here: https://wiki.python.org/moin/TimeComplexity
White Board Talk
If there’s time, we’ll draw some pictures on the white board to see how Python lists are stored in memory and how that affects the Big-O of all these operations.
Points to note:
- Python keeps track of lists in consecutive chunks of computer memory - this data structure is often called an array
- Consecutive memory locations allow $O(1)$ access to items by index in the list - this is often called random access
- Python allocates a certain amount of space for the list. If it outgrows that, it will allocate a new, bigger memory space and copy everything over.
- The worst case for
append()happens when it triggers a re-allocation to the bigger memory space, so it is technically $O(n)$. But, this is guaranteed to happen infrequently enough that it’s still $O(n)$ to append $n$ items, thus thee ammortized worst case for appending one item is $O(1)$, which is why the textbook saysappend()is $O(1)$. For more information, see https://wiki.python.org/moin/TimeComplexity
Here’s a blank memory diagram in case I need to draw digitally