# Instruction Execution Stages copy --- CS 130 // 2022-11-03 <!--====================================================================--> # Datapath and Control Review <!-- .slide: data-background="#004477" --> <!--=====================================================================--> ## Review: Datapath with Control <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' height='500'> <!--=====================================================================--> #### Breaking down instruction execution - Five stages: 1. **IF**: Instruction Fetch - read it from instruction memory 2. **ID**: Instruction Decode and Register Read - split instruction into parts, read register data 3. **EX**: Execute - ALU calculates result 4. **MEM**: Memory Access - we haven't done this yet! 5. **WB**: Write back - put new data back into a register <!--=====================================================================--> ## Example: `addi` ```mips addi $8, $0, 5 ``` 001000 00000 01000 0000000000000101 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - IF: - ID: - EX: - MEM: - WB: </div> <!----------------------------------> ## Example: `addi` ```mips addi $8, $0, 5 ``` 001000 00000 01000 0000000000000101 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - **IF:** PC provides instruction address, bit pattern 001000 00000 01000 0000000000000101 read from memory - 4 added to PC </div> <!----------------------------------> ## Example: `addi` ```mips addi $8, $0, 5 ``` 001000 00000 01000 0000000000000101 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - **ID:** instruction bit pattern split apart into opcode (001000), rs (00000), rt (01000), contant (5). Opcode goes to Control Unit. Value 0 read from register $0 indicated by rs. </div> <!----------------------------------> ## Example: `addi` ```mips addi $8, $0, 5 ``` 001000 00000 01000 0000000000000101 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - **EX:** Value 0 (from $0) and 5 (from instruction constant) added together in ALU. - ALUop set to "add" code - ALUSrc set to 1 - Branch set to 0 </div> <!----------------------------------> ## Example: `addi` ```mips addi $8, $0, 5 ``` 001000 00000 01000 0000000000000101 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - **MEM:** None - MemRead and MemWrite both set to 0 </div> <!----------------------------------> ## Example: `addi` ```mips addi $8, $0, 5 ``` 001000 00000 01000 0000000000000101 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - **WB:** result from ALU (5), written to register $8 (specified by rt) - RegWrite set to 1 - RegDst set to 0 - MemtoReg set to 0 </div> <!--=====================================================================--> # Supporting More Instructions <!-- .slide: data-background="#004477" --> <!--=====================================================================--> ## Load Instruction Let's describe what happens for a load operation like ```mips lw $8, 4($9) ``` 100011 01001 01000 0000000000000100 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - IF: - ID: - EX: - MEM: - WB: </div> </div> <!--====================================================================--> ## Exercise: Store Instruction Describe what happens for a store operation like ```mips sw $8, 4($9) ``` 101011 01001 01000 0000000000000100 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - IF: - ID: - EX: - MEM: - WB: </div> </div> <!--====================================================================--> ## Exercise: Branches Describe what happens for a branch instruction like ```mips beq $8, $9, 5 #jump ahead 5 instructions ``` 000100 01000 01001 0000000000000101 <div class="twocolumn"> <div> <img src='/~manley/CS130/Fall2022/assets/images/COD/datapath_with_control.png' width='500'> </div> <div> - IF: - ID: - EX: - MEM: - WB: </div> </div> <!--====================================================================--> # Performance Issues <!-- .slide: data-background="#004477" --> <!--====================================================================--> ## Performance Issues - Longest delay determines clock period - <!-- .element: class="fragment"--> Some stages of the datapath are idle waiting for others to finish - <!-- .element: class="fragment"--> Can improve performance by **pipelining** <!--====================================================================--> # Pipelining <!-- .slide: data-background="#004477" --> <!--====================================================================--> ## Pipeline Analogy - Suppose you need to do four loads of laundry - <!-- .element: class="fragment"--> Each load of laundry needs to be 1. Washed via the washing machine 2. Dried via the dryer 3. Folded 4. Put away in the closet - <!-- .element: class="fragment"--> For simplicity, assume that each task takes 30 mins <!----------------------------------> ## Pipeline Analogy - How long does it take to complete four loads? - <!-- .element: class="fragment"--> One approach uses only one stage at a time and does nothing in parallel: 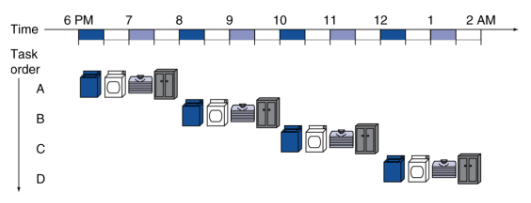 - <!-- .element: class="fragment"--> Notice that the washer is unused 3/4 of the time <!----------------------------------> ## Pipeline Analogy - Another approach is harnessing parallelism by running independent stages simultaneously 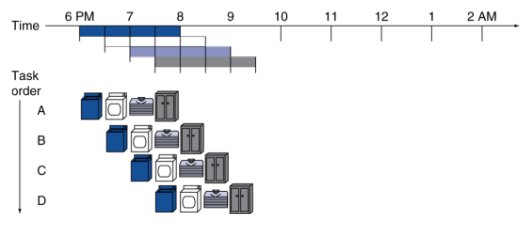 - <!-- .element: class="fragment"--> How much of a speedup does this approach give us? + <!-- .element: class="fragment"--> $8/3.5 = 2.3\times$ speedup + <!-- .element: class="fragment"--> $2n/0.5n = 4\times$ speedup if running continuously <!--====================================================================--> ## Pipelined Datapath <img src='/~manley/CS130/Fall2022/assets/images/COD/piplined_datapath.png' height='550'> <!----------------------------------> ## Pipelined Datapath - Five stages: 1. **IF**: Instruction Fetch 2. **ID**: Instruction Decode 3. **EX**: Execute 4. **MEM**: Memory access 5. **WB**: Write back <!--====================================================================--> ## Pipeline Performance - Assume time for stages is: + `$100\text{ps}$` for register read/write + `$200\text{ps}$` for other stages 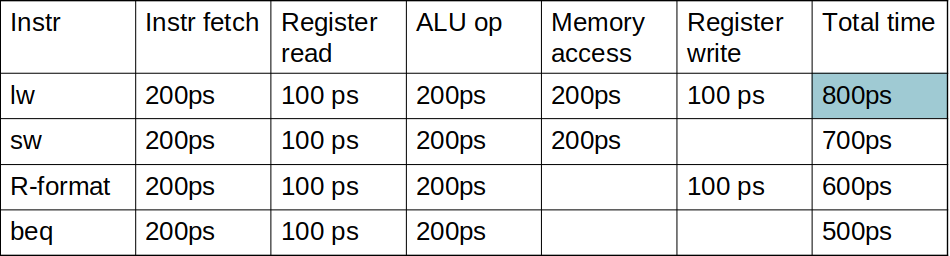<!-- .element: class="fragment"--> <!----------------------------------> ## Without a Pipeline 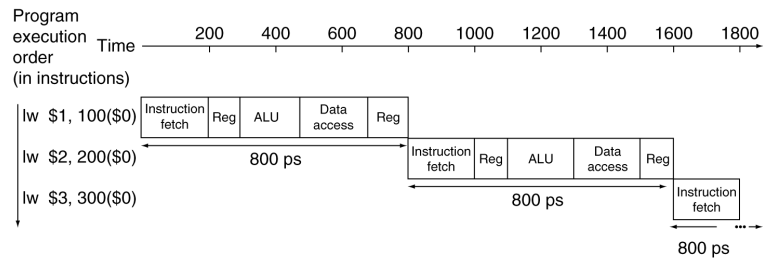 - Why must the clock be set to `$800\text{ps}$` when some instructions like `beq` could be completed in `$500\text{ps}$`? + <!-- .element: class="fragment"--> Clock speed is limited by **slowest** instruction: `lw` <!----------------------------------> ## With a Pipeline 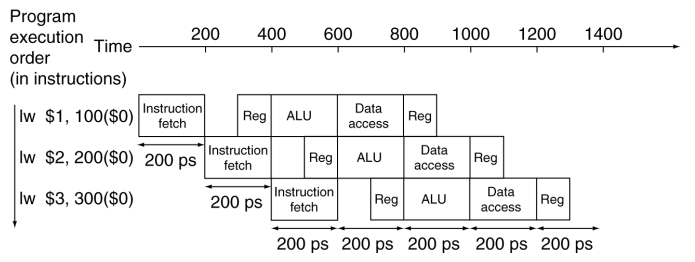 - <!-- .element: class="fragment"--> How much of a speedup does this approach give us? + <!-- .element: class="fragment"--> `$2400/1400 = 1.7\times$` speedup + <!-- .element: class="fragment"--> `$800n/200n = 4\times$` if running continuously <!----------------------------------> ## Pipeline Performance - Does using a pipeline increase the efficiency of executing **individual** instructions? + <!-- .element: class="fragment"--> No, it slows them down from `$800\text{ps}$` to `$1000\text{ps}$` + <!-- .element: class="fragment"--> Performance benefits come from increased **throughput** do to the parallelism <!--====================================================================--> ## Why MIPS is Good for Pipelining - All MIPS instructions are the **same length** + Easy to fetch instruction in cycle 1 + Easy to decode instruction in cycle 2 - <!-- .element: class="fragment"--> MIPS has only **a few instruction formats** + Registers will always be in same location + Easy to decode instructions <!--====================================================================--> # Hazards <!-- .slide: data-background="#004477" --> <!--====================================================================--> ## Hazards - Up until now, we have pretended that each instruction is **independent** of the others and that there are no conflicts - <!-- .element: class="fragment"--> In reality, instructions often depends on previous ones, which may cause naive pipelining to fail <!----------------------------------> ### Exercise ```mips add $s0, $t0, $t1 sub $t2, $s0, $t3 ``` - What stage does `add` write the result of `$s0` into the register file? - What stage does `sub` read from `$s0`? - Why is this a problem? - Can you think of any ways to fix this?